
I am so proud that our financial news summarization model is within 4% of all the 8026 models (in terms of average monthly downloads) in Hugging Face! I would like to thank my colleagues Grigorios Tsoumakas, Tatiana Passali and Alex Gidiotis!
Archive for April, 2021
Hello my AI friends!
Today, I would like to share with you skrobot!
skrobot is an open-source Python module I have created at Medoid AI for automating Machine Learning (ML) tasks. It is built on top of scikit-learn framework and follows object-oriented design (OOD) for ML task creation, execution, and reproducibility. Multiple ML tasks can be combined together to implement an experiment. It also provides seamless tracking and logging of experiments (e.g. saving experiments’ parameters).
It can help Data Scientists and Machine Learning Engineers:
- to keep track of modelling experiments / tasks
- to automate the repetitive (and boring) stuff when designing ML modelling pipelines
- to spend more time on the things that truly matter when solving a problem
The current release of skrobot (1.0.13) supports the following ML tasks for binary classification problems:
- Automated feature engineering / synthesis
- Feature selection
- Model selection (i.e. hyperparameters search)
- Model evaluation
- Model training
- Model prediction
For more information you can check out the online documentation!
Lastly, many thanks to all contributors who helped to extend and support skrobot.
Stay safe!
Hello my friends!
Today, I would like to share with you Time Series Segmentation & Changepoint Detection!
It is an open-source R/Shiny app for time-series segmentation and changepoint detection tasks. The app acts as a front-end for R packages such as the magnificent changepoint package.
I had the pleasure of working together with wonderful colleagues at Medoid AI to develop this application. My role in this small project was more organizational and consulting.
For more information on the parameters and algorithms currently included in the app please read the following paper by Killick et al. For an overview of changepoint packages that may be included in the future please see the following page.
Stay safe!
The last 2 months I have been learning Kubernetes and it has been an exciting journey.
I would like to thank Anestis Fachantidis and my teammates at Medoid AI for motivating me on this learning path as well as Ilias Papachristos for suggesting me to start first with KubeAcademy courses from VMWare!
Furthermore, I would like to thank all the k8s instructors from KubeAcademy for their great work and dedication!
After 25 courses and ~130 lessons I can say that I deserve some rest. Right? Nop 😀
Next Monday I will start preparing for the Google Certified Cloud Architect Certification and it is going to be also an exciting challenge!
Happy deployments!

By passing millions of ImageNet images through InceptionV1 (state-of-the-art deep convolutional neural network) we can extract the image patches that make specific neurons from various convolutional layers to activate mostly.
By projecting the image patches to 2D using UMAP we can see what the neural network “sees” at the various layers.
This is a great way for explaining how a computer vision model makes its classification decision.
However, the following part of the article was the reason for my post:
“….There is another phenomenon worth noting: not only are concepts being refined as you move from layer to layer, but new concepts seem to be appearing out of combinations of old ones….”
This is how a world of complexity works.
We know that deep neural networks perform hierarchical feature learning and combine simpler features to learn more complex ones. This is one of the reasons why we use deep learning for audio, visual and textual data.
Deep learning can decompose the complexity of data!
Have you ever asked why we randomly initialize the weights of a neural network?
After you read this post you will know why!
When the weights of the neurons in a neural network’s layer are initialized to the same value then all neurons of the layer produce the same output in the forward propagation.
Furthermore, when doing backpropagation the gradients of the loss w.r.t to the weights of the layer are also the same values. So, when training happens with gradient descent the weights change in the same way.
Lastly, when gradient descent converges, the weight matrix of the layer contains the same values for all neurons and thus the neurons have learned the same thing.
To break this symmetry and allow the neurons of the layer (and in general in all layers) to learn new and different features we randomly initialize the weights!

Despite the promise of Feature Learning in Deep Learning -where dense, low-dimensional and compressed representations can be learned automatically from high-dimensional raw data- usually Feature Engineering is the most important factor for the success of an ML project.
Among ML practitioners the best learning algorithms and models are well-known and most effort is done to transform the data in order to express as much as possible the useful parts that model best the underlying problem.
In other words, the success of an ML project depends mostly on the data representation and not model selection / tuning. When the features are not garbage usually even the simplest algorithms with default hyperparameter values can give good results.






Dear tech friends!
Recently, I have moved all my open-source projects from GitLab to GitHub and I want to share it with you!
You can find in it various projects I have brainstormed, developed, experimented with the last 17 years.
I hope you will enjoy it and you may find something interested to follow!
Lastly, the last 4 years I am focusing mostly on AI-related projects and I will continue doing it.
Conditional Language Models are not used only in Text Summarization and Machine Translation. They can be used also for Image Captioning!
Here is a great example from Machine Learning Mastery of how we can connect the Feature Extraction component of a SOTA Computer Vision model (e.g., VGG, ResNet, Inception, Xception, etc) with the input of a Language Model in order to generate the caption of an image.
The whole deep learning architecture can be trained end-to-end. It is a simple encoder-decoder architecture but it can be extended and improved using an attention interface between encoder and decoder, or even using Transformer layers!
Adding attention not only enables the model to attend differently various parts of the input image but also explain its decisions. For each generated word in output caption we can visualize the attended visual part of input image.


In Machine Learning we use minimum-disturbance learning algorithms (e.g., LMS, Backprop) to tune the trainable parameters of topological architectures. Instead of programming a model we expose it to observations and let the algorithm find its optimal parameters. So, in this approach the solution to a task is the set of trainable parameters.
In biology, precocial species are those whose young already possess certain abilities from the moment of birth. There is evidence to show that lizard and snake hatchlings already possess behaviors to escape from predators. Shortly after hatching, ducks are able to swim and eat on their own, and turkeys can recognize predators. These species already have abilities before they are even exposed to the world.
Neuroevolution of augmenting topologies is a research field that aims to simulate exactly this behavior. Specifically, neural network architectures can be found that perform various machine learning tasks without weight training. So, in this approach the solution to a task is the topological architecture.
For more information on this idea check the paper “Weight Agnostic Neural Networks“ by (Adam Gaier, David Ha).
The Nelder-Mead method is an optimization algorithm from ’60s and can be used for optimizing multidimensional nonlinear unconstrained functions.
It is a direct method, meaning that it doesn’t use the function’s gradient during optimization. Furthermore, it is a pattern search method, meaning that it uses a pattern of points while searching for the extremum. More specifically, it uses a simplex of n+1 vertexes forming a geometrical pattern to explore the space problem, where n is the number of search space dimensions.
This was just some introduction. Enough with the algorithm logic. Let’s have some fun now!
Did you know that the algorithm sometimes is called also ‘Amoeba method’ ?
The reason is because the simplex geometrical pattern of the method loosely simulates an amoeba that searches for food (the extremum in our case). For example, an amoeba in 2D problems is formed by a triangle and in more dimensions can be more fine-grained. It is funny to see how it moves towards the extremum!
Here is an example of a 2D simplex amoeba evolving in search space to find the minimum of the Rosenbrock banana function.
Happy optimizations!

Natural languages (speech and text) are the way we communicate as species. They help us to express whatever is inside to the outer world.
Natural languages are not designed. They emerge. Thus, they are messy and semi-structured. If they were designed, NLP would be already solved, using context-free grammars and finite automata by linguists 50 years ago.
Today, we are trying to artificially “learn” language from text using state-of-the-art Deep Neural Language Models that behave probabilistically, predicting the next token in a sequence.
Moreover, natural languages are not static. They evolve and change. Different words can be used in different times with different meaning. It is a moving target.
Plato, the Greek philosopher was negative with “languages” -despite the fact the he has written so much- because a language cannot express the fullness of a human mind, of a person. Socrates and many philosophers from the Peripatetic school never wrote texts. The only way they were communicate was by real human communication (body language, eyes, speech, touch). Only with this way, a human mind and heart can evolve and create new worlds.
However, we are living in a century where everything is either digitalised or written and human communication goes to minimum.

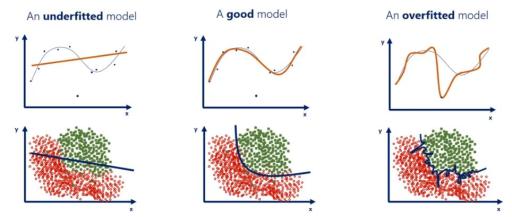
Assume a train/validation/test split and an error metric for evaluating a machine learning model.
In case of high validation/test errors something is not working well and we can try to diagnose if it is a high-bias or high-variance problem.
When both the training and validation errors are high then we have a high-bias model (underfitting). When we have a high validation error and low training error we have a high-variance model (overfitting).
Also, there is a case where both validation and training errors are low but test error is high. This can happen either because we test the model in data from a different world (different data distribution) or we have overfitted to the hyperparameters on validation data, same as when overfitting the models’s parameters on training data.
Machine Learning practitioners always focus on finding in an unbiased way models where validation and training errors are low. When it happens, we say “this a good fit” and then we monitor the model on unseen test data to see how it performs in the real world.
Linear / Logistic regression learning algorithms can be used to learn surfaces to fit non-linear data (either for regression or classification).
It can be done by adding extra polynomial terms (quadratic, cubic, etc) in the dataset using the existing features. The approximated surfaces can be circles, ellipses, parabolas and hyperbolas.
However, (1) it is difficult to approximate very complex non-linear surfaces. Also, when the features are many then (2) it is very computationally expensive to calculate all polynomial terms (eg: for a 100×100 grayscale images we need 100000 quadratic terms).
Usually, due to the limitations (1) and (2) we either perform dimensionality reduction to reduce the number of features (eg: eigenfaces for face recognition) or use more complex non-linear approximators such as Support Vector Machines and Neural Networks.

Some personal notes to all AI practitioners!
In Linear Regression when using the loss function MSE it is always a bowl-shaped convex function and gradient descent can always find the global minima.
In Logistic Regression if we use the MSE then it will not be a convex function because the hypothesis function is non-linear (it uses a sigmoidal activation). Thus, it will be harder for gradient descent to find the global minima. However, if we use the cross-entropy loss it will be convex and gradient descent can easily converge to global minima!
Support Vector Machines have also convex loss function.
We should always use a convex loss function so that gradient descent can converge to the global minima (local optima free).
Neural Networks are very complex non-linear mathematical functions and the loss function most often is non-convex, thus it is usual to stuck in a local minima. However, most optimization problems in Neural Networks are due to long plateau and saddle points rather than local minima. For such problems advanced gradient descent optimization variants were invented (eg: Momentum, Adam, RMSprop).
Happy optimizations!

How much AI and Machine Learning are related to ancient Greek Philosophy? More than you imagine!
In this article you will learn about the never ending debate between Platonic and Aristotelian ideas of the reality of the world.
In my opinion, I agree with Plato saying that the world we experience is just a shadow of the real one. One possible interpretation can come from modern physics with theories such a) multidimensional world (e.g. string theory, theory of relativity) b) quantum physics and c) non-Euclidean geometrical spaces. Things are not as they appear in our brains. We see only a projection of the real world and we are totally living in a matrix limited by our physiology.
However, I agree also with Aristotle saying that the forms of entities reside only in the physical world. So, the “ideal” forms are learned by our brains and do not pre-exist.
The article touches the issue of Universals and Particulars in Philosophy and tries to explain them also in terms of Machine Learning. Machine Learning models learn to separate the universal (signal) from the particulars (noise) from observed data of the world.

Before AI we were “programming” computers.
In this context a programmer creates a program to solve a specific problem using data structures and algorithms. After that, we can run the program with some input data to produce some output. Let’s call this Traditional Programming.
Nowadays, with AI we are “showing” computers.
In this context a programmer shows to a learning algorithm input and output data for a specific problem to be solved. The program is automatically created by the learning algorithm. After that, we can run the program with some new input data to produce its output. Let’s call this Machine Learning.
Nowadays, computer science departments in universities teach most the Traditional Programming mindset. For boosting an AI-powered society it would be wise to teach equally Machine Learning!



