Assume a train/validation/test split and an error metric for evaluating a machine learning model.
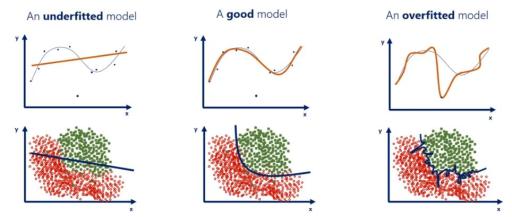
In case of high validation/test errors something is not working well and we can try to diagnose if it is a high-bias or high-variance problem.
When both the training and validation errors are high then we have a high-bias model (underfitting). When we have a high validation error and low training error we have a high-variance model (overfitting).
Also, there is a case where both validation and training errors are low but test error is high. This can happen either because we test the model in data from a different world (different data distribution) or we have overfitted to the hyperparameters on validation data, same as when overfitting the models’s parameters on training data.
Machine Learning practitioners always focus on finding in an unbiased way models where validation and training errors are low. When it happens, we say “this a good fit” and then we monitor the model on unseen test data to see how it performs in the real world.