
The following program generates N random integers between 0 and 999, creates a linked list inserting a number in each node and then rearranges the nodes of the list so that the numbers appear sorted when we go through the list. For the sorting, it maintains two lists: one input list (not sorted) and one output list (sorted). In each iteration of the loop, it removes a node from the input list and enters it in the appropriate position in the output list. The code is simplified by using head nodes for each list, which contains links to the first node lists. Also, both lists (input and output) are printed.
Latest Entries »
This program demonstrates the use of an array and is representative of the usual situation in which we store data in one array to process them later. It counts the number of pairs of N randomly generated points of the unit square, which can be connected to a line segment of length less than ‘d’, using the point data type. Because the execution time of this program is O(n2), it can’t be used for large N.
The function ‘reverse’ in the following example reverses the links in a list, returning a pointer to the end node, which then shows the next of the last node, and so forth, while the link to the first node of the initial list is assigned the value 0 corresponding to null pointer (in C++). To accomplish this task, we must maintain links to three consecutive nodes in the list.
For the representation of individuals arranged in a circle, we create a circular linked list with a combination of each person to the person on his left in the circle. The integer i represents the i-th person in the circle. After you create a circular list of one node for 1, we insert its unique node to nodes 2 to N. We end up with a cycle from 1 to N, with x indicating the node N. Then, starting from 1 we omit M-1 nodes, we define the pointer of the (M-1)-th node to omit the M-th, and continue that way until only one node remains in the list.
The aim of this program is to assign to a[i] the value 1 if i is a prime number and the value 0 if not. Initially, all elements of the array take the value 1 to indicate that there are no numbers which are known not to be prime. Then all elements of the array corresponding to indexes that are known not to be primes (multiples of known primes) take the value 0. If a[i] has the value 1 even after all multiples of smaller primes have taken the value 0, we know that i is a prime number.
The program generally simulates a Bernoulli trials sequence, a familiar and abstract notion of probability theory. So, if you flip a coin N times, we expect “head” to occur N/2 times – but it could occur anything between 0 and N times. The program performs the experiment M times, reading the N and M from the command line. It uses an array ‘f’ to count the frequency with which the result “i heads” appears for 0 <= i <= N, and then displays a histogram of the results of experiments with an asterisk for every 10 appearances. Also, the operation behind the program – of indexing an array with a calculated value – is critical to the effectiveness of many computational procedures.
Sequential Search.
This algorithm checks whether the number ‘v’ is contained in a set of numbers already stored in the data a[0], a[1], …, a[r-1] of the array ‘a’ (where ‘r’ the number of elements in it), comparing it sequentially with all numbers, starting from the beginning. If the check reaches the end without finding the number, the value -1 is returned. Otherwise, we are returned the index of the position of the one-dimensional array containing the number.
This project refers to an Arduino library implementing a generic, dynamic queue (array version).
The data structure is implemented as a class in C++.
For more information, you can get the project itself ‘QueueArray‘.
If we replace the loops ‘for’ of the simple version of weighted quick-union (you’ll find it in a previous article) with the following code, we reduce the length of each route passing to the half. The end result of this change is that after a long sequence of operations the trees end up almost level.
This program reads from the standard input a sequence of pairs of non-negative integers which are less than N (interpreting the pair [p q] as a “link of the object p to object q”) and displays the pairs that represent those objects which are not yet connected. The program complies with the array ‘id’ to include an entry for each object and applies that id[q] and id[p] are equal if and only if p and q are connected.
If we replace the body of the while loop of the quick-find algorithm (you can find it in a previous article) with the following code we have a program that meets the same specifications as the quick-find algorithm but performs fewer calculations for the act of union, to the expense of more calculations for act of finding. The ‘for’ loop and the ‘if’ operation that follows in this code determine the necessary and sufficient conditions in the array ‘id’ that p and q be linked. The act of union is implemented by the assignment id[i] = j.
This program is a modification of the simple quick-union algorithm (you’ll find it in a previous article). It uses an extra array ‘sz’ to store the number of nodes for each object with id[i] == i in the corresponding “tree”, so the act of union to be able to connect the smaller of the two specified “trees” with the largest, and thus avoid the formation of large paths in “trees”.
This project refers to an Arduino library for implementing a generic, dynamic queue (linked list version).
The data structure is implemented as a class in C++.
For more information, you can get the project itself ‘QueueList‘.
This project refers to an Arduino library implementing a generic, dynamic stack (linked list version).
The data structure is implemented as a class in C++.
For more information, you can get the project itself ‘StackList‘.
In this article, I quote a personal documentation implementation of the source code of the application “GNU Find String” using the Doxygen system. The source code of the application is written in ANSI C. You’ll find the documentation here: Doxygen documentation of the source code of the application “GNU Find String”.
The presence of errors in software development (and not only) is inevitable. However, over time the programs improve and tend to perfection through various techniques and methods we have developed.
The deterministic problems are easy to spot because they always lead to the same error. There are tools that run through the source code of an application to find possible deterministic errors (these tools are especially useful in applications written with scripting languages such as Python, Bash Scripting, etc).
The QT provides an adorable way to store the settings of a program with a GUI (and not only) by means of the QSettings library. Below, we quote a personal version of the project ‘parkman‘ (Parking Manager).
Below I quote a simple but useful library (implemented in C++) which contains functions for comparing double precision floating point numbers.
The Ben 10 cube presented enough interest. Although it is like the classic Rubik’s cube, it had some peculiarities.
Specifically, in order to solve it you need to concentrate your attention on the central square of each side so you can always orient it accordingly in the right direction to finalize plans without irregularities.
Within the framework of the course “Programming II – Laboratory” (Department of Informatics and Communications, T.E.I. of Central Macedonia) we were asked to implement as homework a program that reads characters from the standard input and then export to standard output a frequency histogram of the characters that appear.
 This project refers to an Arduino sketch which is used to produce LEDs animations. So, we use an 8-bit shift register (namely the 74HC595). This way we can drive 8 different LEDs in the output committing only three PINS of the Arduino.
This project refers to an Arduino sketch which is used to produce LEDs animations. So, we use an 8-bit shift register (namely the 74HC595). This way we can drive 8 different LEDs in the output committing only three PINS of the Arduino.
If we want to drive more LEDs, we connect into a cascade form two or more (depending on the number of LEDs we want to support) shift registers and act accordingly.
Within the framework of the course “Numerical Methods in Programming Environments – Theory” (Department of Informatics and Communications, T.E.I. of Central Macedonia) we were asked to develop an optional program that implements Müller’s numerical method for finding the root of equations of the form f(x) = 0.
A nice problem that intrigued me is the “Rubik’s Magic”. I could solve the problem fast enough. In the beginning, I thought it to be quite difficult. But I finally was able to join the three rings with little effort.
I will always post my best solutions on this post. I try to set up personal records.
Surely, I can not compete with the champions but I think I will one day reach their standards with continued practice.
Personal record: 5 seconds.
Since I got my hands on Rubik’s cube, namely the classical one (3x3x3) I got hooked on solving it. I tried several times to solve it but more often I smashed it on the wall or give up.
But recently I learned that Rubik’s cube is solved with algorithms. So when I learned the algorithms and the solution methodology, I started with good intentions. So after a while, I could solve it by applying the algorithms. I have also solved the cubes with 2x2x2, 4x4x4, 5x5x5 and 6x6x6 dimensions. Knowing how to solve these cubes, you can solve any major dimension ones. In larger cubes, there are likely more parity errors. This does not prevent you from solving them.
It was a very interesting experience for me to participate in the mission of the Department of Informatics and Communications of the T.E.I. of Central Macedonia in Thessaloniki, where the Department took part in the Infosystem 2009 exhibition.
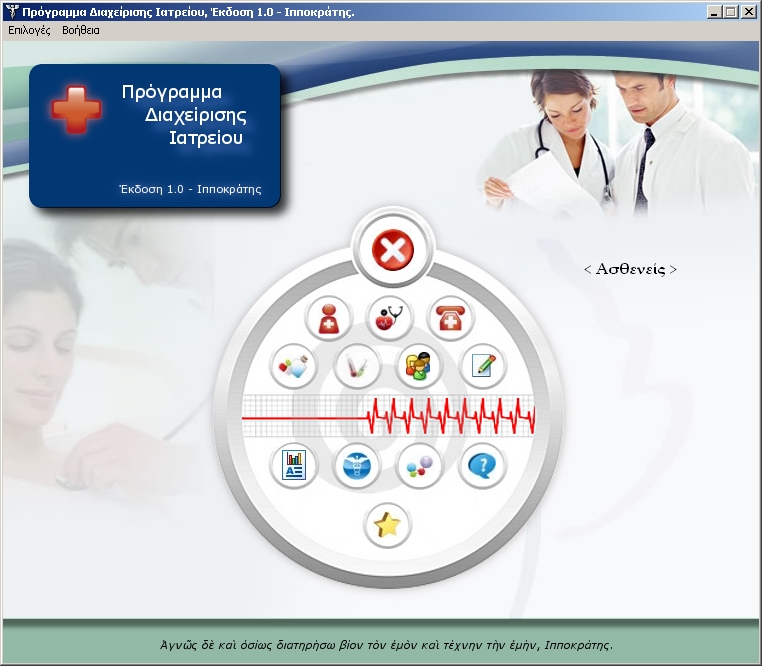 Within the framework of the course “Visual Programming – Theory” (Department of Informatics and Communications, T.E.I. of Central Macedonia) we developed a clinic management application as a semester project.
Within the framework of the course “Visual Programming – Theory” (Department of Informatics and Communications, T.E.I. of Central Macedonia) we developed a clinic management application as a semester project.
The database of the application was implemented in Microsoft SQL Server and the graphical user interface in Borland C++ Builder.
More specifically, this application enables the end user to manage different patients, visits, appointments, diagnoses, treatments, prescriptions, tests, links.
Rubik’s 360 Sphere is quite interesting. Once you understand how it works, the solution is then quite easy. Specifically, you need to concentrate your attention on the two axes as well as the two pendulums that are found inside the spheres.
The project ‘dec2bin’ (decimal to binary converter) is the implementation of an idea I had for some time. I have to admit that sometime in the past when studying possible ways of programming embedded systems with the programming language C and C++, I felt the need to be able to produce, through a program, supposed memory addresses in the form of binary numbers.
A beautiful and dynamic experience that I hope will be repeated again.
Congratulations to the organizers and participants of this conference.
Their contributions to Free Software was invaluable.
")


